 |

|
Septiembre 2008 |
Newsletter de Business
Intelligence |
N°6 |
| En este Newsletter...
|
Temas
abordados en esta edición:
- Análisis de Supervivencia - Pervasive Business Intelligence |
| Análisis
de Supervivencia en Marketing y Data Mining Las
disciplinas de marketing y data mining tienen cierta intersección
en lo que se refiere a su aplicación a la gestión
de la relación con los clientes, área habitualmente
conocida como CRM. Tareas como la identificación de los prospectos
para campañas focalizadas, la predicción de qué
clientes tienen una probabilidad significativa de cese o mora, cuál
sería la tasa de respuesta de una campaña de ventas,
la tasa de adquisición de un nuevo producto o servicio, y
tantas otras son rutinariamente realizadas dentro de ambas disciplinas.
Las herramientas principales son el desarrollo de modelos predictivos
basados en técnicas estadísticas que, a partir de
una caracterización individual de cada cliente, pueden predecir
la probabilidad de que éste incurra en algún suceso
deseado o no deseado. La mayoría de las técnicas típicas seleccionan un conjunto de personas o clientes según la probabilidad de ocurrencia de un determinado suceso (respuesta, activación, churn, etc.). Sin embargo, es posible una perspectiva que haga un mejor uso de lo que sabemos de los clientes, es decir, un enfoque menos “miope”. En base a lo que conocemos de cada cliente podemos asociar a cada uno un “valor”. En una perspectiva a mediano plazo, ese valor está asociado a su ciclo de vida como cliente. Una persona que tenga una probabilidad alta de responder a una campaña de marketing, pero que se encuentra en la zona de “declinación” de su ciclo de vida, puede ser un target seleccionable, aunque no tan interesante como otra persona con una probabilidad de respuesta menor pero que recién inicia la relación y tiene una amplia perspectiva de cross-selling y upselling durante un plazo de mediana duración. El valor de tiempo de vida de esta segunda persona es bastante mayor que el de la primera, de modo que estaríamos dispuestos a invertir en contactarlo (aun cuando su probabilidad de respuesta sea menor) en vista de futuras ganancias. Estas consideraciones permiten que un modelo predictivo pueda ser más efectivo y beneficioso en un mediano plazo (algunos pocos años). Para un cálculo apropiado del valor de tiempo de vida necesitamos complementar las técnicas tradicionales con otras más aptas para modelizar los factores temporales involucrados. Por otro lado, aunque en relación con lo anterior, existe un conjunto grande de preguntas que los modelos predictivos convencionales no pueden contestar. Por ejemplo, ¿cuánto tiempo durará la relación con un cliente?, ¿cuándo empezar a preocuparse si un cliente no se reactiva, no responde, no cancela una cuota, etc.?, ¿cuándo ocurrirá la próxima transacción, compra, consulta, etc. de un cliente?, ¿cuál es el efecto de diversos factores sobre la duración de la relación con el cliente?, y otras tantas preguntas por el estilo. Lo que todas estas preguntas y los cálculos de valor de tiempo de vida del cliente tienen en común es la necesidad de incorporación efectiva de un análisis de la dimensión temporal. Los métodos tradicionales en marketing y en data mining sirven para predecir la ocurrencia de sucesos específicos en un intervalo relativamente corto de tiempo, no cuándo ocurrirán distintos tipos de sucesos (por ejemplo, sirven para predecir qué clientes desertarán el próximo mes, pero no para pronosticar cuándo desertarán nuestros clientes dentro de los dos próximos años). Los métodos tradicionales para tratar los fenómenos temporales, el llamado análisis de series de tiempo, tiene el enfoque equivocado desde el punto de vista del marketing: trata los sucesos de un modo agregado (el número total de clientes que realizará alguna conducta), perdiendo de vista el foco en el individuo (cuándo un cliente determinado realizará la conducta). Es aquí donde el análisis de supervivencia puede complementar muy eficazmente los métodos tradicionales. Agrega el elemento de cuándo ocurren las cosas. La supervivencia es particularmente valiosa para ganar comprensión de los clientes y cuantificar esa comprensión. En términos generales, permite predecir cuándo ocurren sucesos particulares, comprender qué factores afectan el cuándo y cuantificar qué ocurre a lo largo del tiempo. El análisis de supervivencia tiene su origen a finales del siglo XVII. La primera referencia conocida es la de un trabajo de 1693 de Edmund Halley (el descubridor del cometa Halley) sobra la estimación de la tasa de mortalidad. Desde entonces el análisis de supervivencia fue usado principalmente por actuarios hasta el siglo XX. En este siglo la disciplina se desarrolló considerablemente y fue utilizada en diversas áreas incluyendo la medicina y el control de calidad (aunque existieron algunos pocos precedentes en siglos anteriores). A comienzos del siglo XXI fue introducida al marketing y data mining por Michael Berry y Gordon Linoff, dos matemáticos estadounidenses que trabajan en estas áreas. Tal vez las diferencias entre la aplicación del análisis de supervivencia en medicina o control de calidad y marketing o data mining sea lo que explique la demora en la adopción de este conjunto de técnicas por parte de estas últimas disciplinas:
Las desemejanzas anteriores marcan profundas diferencias en la forma en que el análisis de supervivencia se aplica en medicina y control de calidad por un lado y en marketing y data mining por el otro. A nivel conceptual, las herramientas del análisis de supervivencia son el riesgo (sólo una probabilidad condicional) y la supervivencia (la probabilidad acumulada de que un suceso no ocurrirá). Las curvas de riesgo y de supervivencia son herramientas gráficas y analíticas fundamentales para modelizar el ciclo de vida de los clientes, cuantificar factores como la retención (fundamental para el cálculo del tiempo de vida) usando medidas como el tiempo de vida medio de un cliente, detectar sucesos conocidos o inesperados, etc. Otras técnicas, permiten realizar una diversidad de análisis: estratificación en las curvas de supervivencia para determinar el efecto de distintas causas sobre un suceso y su tiempo de ocurrencia, ventanas temporales para resolver problemas de truncado izquierdo (fenómeno frecuente que ocurre cuando se pierde información histórica de los clientes debido, por ejemplo, a migraciones de las bases de datos, algo que afecta perjudicialmente a muchos análisis estadísticos), métodos de regresión especiales (la regresión de Cox y otras surgidas de ésta) para la modelización del efecto de covariables y riesgos competidores sobre el suceso de interés, y tantas otras.
Brown cheap hair extensions is a favorite choice for many people. real hair extensions is because it is safe enough to be close to black, hair extensions and charming.
En síntesis, ya sea para adoptar criterios de selección de clientes más provechosos en un mediano plazo como para incorporar los aspectos temporales de tantos fenómenos de interés en el mundo del marketing o el data mining, es preciso complementar las técnicas tradicionales con las provenientes del análisis de supervivencia. La sinergia de ambas permite un análisis de mayor amplitud y precisión que resulta muy favorable en el área de inteligencia de negocios. Para consultar:
|
Pervasive Business Intelligence (BI) A pesar de los considerables esfuerzos de vendors y grandes consultoras, se estima que la penetración de las herramientas de BI en una organización es de cuanto más un 24% de su personal. Los fabricantes de software progresan en el desarrollo de interfases cada vez más amigables, componentes más integrados y eficientes, análisis en memoria, visualizaciones de datos e indicadores, etc. para incrementar la penetración de sus herramientas. Las grandes consultoras, partners en su gran mayoría de uno o más vendedores de software, se esfuerzan por facilitar y acortar los plazos de desarrollo e implementación de los proyectos de BI. Sin embargo, todos estos esfuerzos aun no resultaron demasiado eficaces. Una reciente investigación del Data Warehousing Institute revela las principales causas de este estado de cosas. Pueden distinguirse dos componentes necesarios en la penetración de las herramientas de BI: adopción (disponibilidad) y utilización. Cada uno experimenta diversos problemas. La adopción requiere la adquisición de licencias
para los usuarios y, especialmente, la instalación, desarrollo
y despliegue de las herramientas. Existen varios obstáculos
importantes en la adopción de herramientas de BI. La más
importante es el tiempo y complejidad de una implementación.
En un nivel departamental las implementaciones suelen tener una
complejidad y costo razonables, pero estos escalan abruptamente
cuando se pasa al nivel de toda la empresa. Por lo general, una
implementación de BI posee herramientas de consulta, reporting
y análisis sofisticadas que deben integrarse con los sistemas
de seguridad, backup y otros de la empresa. La integración
de las herramientas de BI con servidores de aplicaciones Web y sistemas
de bases de datos es una fuente de problemas agregados. Los intentos
de los vendors por facilitar la integración de sistemas propios
y de terceros contribuyen en algo a mejorar este estado de cosas,
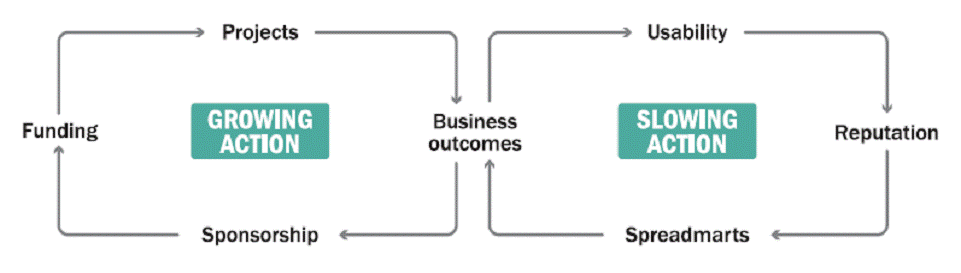
pero ninguno ha resultado hasta ahora suficientemente exitoso. Los obstáculos para el uso de BI son varios y según la investigación de TDWI, muchos de ellos tienen un impacto similar. Entre los mencionados se encuentran: los usuarios prefieren otros métodos o herramientas, errores percibidos en los datos, percepción por parte de los usuarios de que son herramientas demasiado complejas, tiempos de respuesta demasiado prolongados para las consultas, falta de respaldo de los ejecutivos, demasiados informes o carpetas, funcionalidad insuficiente y uso inadecuado de herramientas de monitoreo. Un bajo nivel de calidad de datos constituye un obstáculo importante también. Los usuarios perciben favorablemente un conjunto de herramientas y estrategias que los vendors se encuentran implementando y los consideran buenos recursos que contribuyen a aliviar los obstáculos anteriores: integración con Office, tableros de control, salidas de BI anidadas en procesos, alto nivel de interactividad y “autoservicio” en las herramientas de reporting, acceso mediante clientes delgados a los reportes, marketing y educación continua, entrenamiento y troubleshooting a demanda. Sin embargo, aun no han tenido el impacto deseado y de cualquier forma son insuficientes para obtener la meta de un “BI penetrante”. La misma investigación de TDWI muestra dos escenarios distintos en los proyectos de implementación de BI que pueden llevar a problemas complementarios: uno basado en un ciclo de reforzamiento positivo en el cual una implementación exitosa no alcanza nunca a satisfacer la demanda de los usuarios (provocando entonces la insatisfacción de estos) y otro basado en un ciclo de reforzamiento negativo en el que una implementación no consigue generar una tasa de adopción razonable por parte de los usuarios potenciales. Comprender estos mecanismos puede contribuir a desarrollar estrategias para resolver frecuentes problemas de implementación. Un modelo sistémico de la dinámica de las implementaciones de BI puede representarse de la siguiente manera:
El modelo está básicamente compuesto por dos ciclos adyacentes, uno de reforzamiento positivo (acelera la utilización de BI) y otro de reforzamiento negativo (inhibe el desarrollo del BI en una empresa). Ambos ciclos tienen un punto de conexión en los resultados de negocios. En el ciclo negativo, las falencias en la usabilidad de las herramientas de BI producen una mala reputación del equipo y proyecto de BI, y generan “spreadmarts”, sistemas generalmente locales generados fuera del ámbito de IT para resolver los problemas de individuos o pequeños grupos. La percepción de lo anterior provoca cuestionamientos desde el nivel ejecutivo, recortes de fondos y apoyo, lo que debilita aun más el estado del proyecto de BI. El ciclo se realimenta hasta que el proyecto es cancelado o el equipo de BI encuentra una manera de salir del ciclo negativo. En el ciclo positivo, una vez que un proyecto de BI demostró que puede reducir costos, aumentar ingresos, estimular el interés de sus usuarios naturales, etc., esto genera un interés, de parte de los ejecutivos, por aumentar fondos e implementar nuevos proyectos relacionados, para agregar más valor. Este ciclo de reforzamiento positivo se acelera hasta encontrar límites naturales al crecimiento. Cuando el equipo de BI se vuelve demasiado grande como para poder funcionar eficientemente, o cuando arquitectura y estándares se vuelven demasiado pesados como para satisfacer las demandas en un tiempo razonable, comienzan a generarse insatisfacciones que producen una desaceleración del ciclo. Esta dinámica exige al equipo de BI un continuo monitoreo del proceso y una determinación lo más temprana posible de en qué sitio se encuentran en uno de los dos ciclos. Por otra parte cada uno de los elementos de ambos ciclos ofrece múltiples puntos de intervención para encauzar un proyecto en las vías apropiadas. La investigación de TDWI produce unas cuantas sugerencias al respecto. Para consultar:
|
| Si no quiere seguir recibiendo este Newsletter por favor enviar un mail de respuesta colocando "EXCLUIR" en su título. |